Syncing Letterboxd Data to Markdown Files

Update 2024-03-11: I have updated things to ESM.
About two years ago I used Xavi Benjamin’s handy blog post display my Letterboxd diary info on my Eleventy site. At the time I noted on Twitter:
Why use Letterboxd instead of building it into my own site, like my reading log? Letterboxd is actually nice to use, for one, whereas Goodreads being terrible is why I decided to roll my own
(I also thought that Letterboxd had a public API and I could pull it into my Eleventy build process if need be, but it looks like API access is still in Beta)
Well, the idea of being able to keep that data locally on my site never left my brain.1 It was nice to dynamically source the data at build time, but Letterboxd’s RSS feeds top out at 50 items, so I couldn’t display an ever-growing log. Plus it felt important to view Letterboxd as an outlet for my information, not the sole keeper of it. So a few weekends ago I rolled up my sleeves and put together a small CLI utility. I already had some useful data scraping bits in another CLI tool that I use to prep my reading log, so I combined that with a fork of the letterboxd package. I ended up forking letterboxd for two reasons:
- I needed the CommonJS version, and the last release of
letterboxdswitched to ESM - I needed to add a method to return the diary entry as Markdown
letterboxd-to-markdown #
The result is here: letterboxd-to-markdown. The script installs a letterboxd command that does one thing: fetches the RSS feed for a Letterboxd account and converts the diary entries to Markdown files, with a folder for each film.
It’s basically two methods, and it should be easy to modify the data that gets written to the Markdown front matter if you want other details from your diary (I don’t use star ratings, for example).
Getting things into Markdown is useful from an archival standpoint alone, but the next step was integrating it into my site.
Using this with Eleventy #
I copied the approach of my hand-built reading log, and at the root level of my Eleventy site I created a folder called watching, with a watching.json file that defines a content type film. I set this as the output directory, so that when I run letterboxd it fills my watching directory with the folders of all my films.
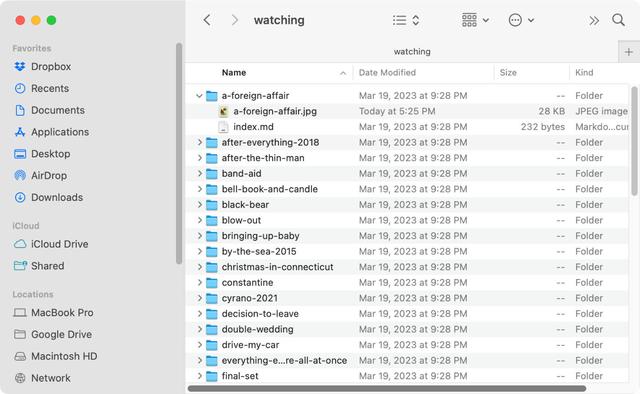
Within my .eleventy.js file I defined a watching collection that aggregates all of those film folders and also gives me sub-groupings by year. If you’re interested in the code details, my site is on Github.2
Build #
To automate the process further I added an entry in my package.json file to run letterboxd before doing an eleventy build:
"scripts": {
"build": "eleventy",
"watch": "eleventy --watch",
"serve": "eleventy --serve",
"debug": "DEBUG=* eleventy",
"film": "letterboxd diary -a dirtystylus && eleventy"
},Results #
I was able to reuse most of the templates I had in place for my reading log. I’m still pretty happy with that CSS Grid code, although for movies the detail pages probably need a bit of rethinking, since my Letterboxd diary entries tend to be pretty short.

While building this I kept thinking back to the early 2000s and how I would pull stuff from Twitter and Flickr into my site. Not much has changed in technical approach, I guess, but now I’m a lot more wary about the longevity (and use) of my data on other platforms. (Yesterday’s news about DPReview shutting down certainly didn’t help.)
Ethan Marcotte said “Let a website be a worry stone” and I haven’t forgotten. ↩︎
Yes, it’s called
eleventy-test. Sometimes you just run with a thing that’s working. ↩︎